
Have you found one of the pages on your website is a bit of a rotten apple and hasn’t been indexed on Google, while other URLs are indexed and possibly even thriving?
Maybe that URL is not so rotten, after all, but it’s just a bit different like, say, a purple rubber ducky among a sea of yellow ones and it’s just needs a little extra nurturing.
This article will provide comprehensive a technical SEO troubleshooting checklist for a URL that is not indexed along with the not-so-common nor well-known solution to the page we were having issues with.
For the technical crowd, you’ve probably gone through the basics already but your unindexed URL will likely be showing one of these statuses/errors in Google Search Console:
- Page is not indexed: URL is unknown to Google
- Page is not indexed: Duplicate without user-selected canonical
- Page is not indexed: Discovered – currently not indexed
- Page is not indexed: Crawled – currently not indexed
TLDR; Here are the 9 Fixes to Get Your Page Indexed:
- Change the URL. Keep the content the same but change the page URL (slug) and request indexing of the “new” page. more
- Build More Links. Develop more internal and external links to the page to increase its prominence. more
- Disavow Spammy Backlinks. A suspect backlink profile may be deterring Google from prioritizing your site indexing. more
- Resolve UserAgent Discrepancies. Verify that fetching the page as the Googlebot UserAgent produces a page rendering that is not too different from that of a normal browser. more
- Intermittent Server-side Errors. Check the Google Search Console crawl report for server-side errors (e.g. 510/504 HTTP responses) and compare against server logs and Google Analytics traffic reports. more
- Wrong Canonical. Google may have chosen a canonical source for the page’s content that is different from the one you had explicitly set. more
- X-Robots Tag Noindex. The page may have been noindexed using X-Robots. more
- Dropped HTML Tags. If some HTML tags were dropped, Google may not be able to fully read and crawl the content. more
- Try Backlink Indexers and Google Indexing API. Consider using one or more backlink indexer tools as a last resort, including the Google Indexing API (spoiler – this is what fixed our issue). more
One of the biggest challenges for website owners and marketers is making sure Google not only discovers their pages, but also indexes them so they can appear in search results.
Unfortunately, it’s not uncommon for web pages to be discovered by Google’s crawlers but not indexed, preventing them from showing up in search results and making them invisible to potential visitors.
So, if your website pages are not getting indexed in Google, but instead you are seeing one of the errors above showing up in Google Search Console, your site may have an uncommon indexation issue. Something is preventing your pages from being indexed by Google. It may be content rendering – JavaScript is preventing Google from rendering important parts of your page during indexation. Or HTML tags are dropped in your rendered HTML. Whatever the indexing issue is, there’s a fix for it.
This post will go through a comprehensive checklist of search engine / Google indexation issues for an individual page (or a group of pages) on a website that nevertheless has many other pages that are indexed. We’ll also discuss several potential solutions.
If this article doesn’t help solve your indexing problem, you can contact us via the chat box below. Not only do we offer technical SEO consulting but we also provide a full range of digital marketing services.
What Does “Discovered – Currently Not Indexed” Mean?
You’ve found one of the pages on your site hasn’t been indexed on Google. This is a completely different, and typically more complex, issue than an entire website that is not indexed. However, the checkpoints found in this article will still help troubleshoot an entire website that is not indexed.
Your indexation issue may have been identified in any number of ways:
- Basic search for a term with or without the site:domain.com operator.
- No organic hits reported in analytics
- URL is not on Google status in Google Search Console’s URL Inspection Tool
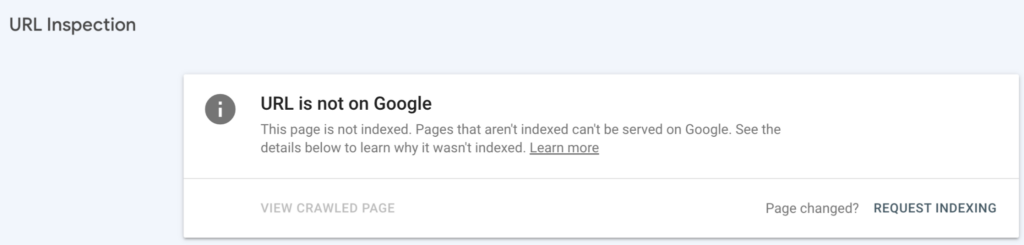
The URL Inspection Tool within Google Search Console (hereafter, “GSC”) is where you should begin this troubleshooting journey if you haven’t checked already.
GSC contains many reports to help diagnose this problem and the inspection tool will give you more details on the error after inputting the URL.
4 common errors displayed in the Inspect URL report are:
- Page is not indexed: URL is unknown to Google
- Page is not indexed: Duplicate without user-selected canonical
- Page is not indexed: Discovered – currently not indexed
- Page is not indexed: Crawled – currently not indexed
The first error above, “URL is unknown to Google,” is a straightforward fix. Typically the URL is misspelled when entered into the tool, or it’s missing from the sitemap.
The second error relates to Google being confused about which is the canonical version of a page. On a basic level, the error is simply having forgotten to add in a canonical tag to your page: <link rel=”canonical” href=”https://company.com”>. Note that popular WordPress plugins like Yoast and RankMath do this automatically, so if you’re using those, then the error may be more nuanced.
The “duplicate” page part of the error arises from three likely sources:
- Duplicating an existing page and forgetting to update it: the pages will have different URLs, but the same content and the same canonical.
- URL-appended parameters to a dynamic page can trigger server-side code that renders a different page depending on the parameters, often without a canonical. For example, in WordPress these URL parameters trigger server-side functions – and typically do not include a canonical tag:
- mycompany.com?p=5 – this returns (or redirects to) blog post with ID #5
- mycompany.com?s=discounts – this returns the results of a site search for the word “discounts”
For the third and fourth errors, where a URL has been reported as “Discovered – currently not indexed” or “Crawled – currently not indexed,” the issue is significantly more complex and can be caused by more than one factor, so we’ll be focusing on this error.
“Discovered” means that Google’s spider has found a link to your page, either:
- internally on your site
- externally somewhere on the Web
- in one of your sitemaps
- from your own manual request to index it or via a programmatic Indexing API (for certain types of pages, like job posts and events)
The status “discovered” is different from “crawled” and “indexed,” as follows:
- Discovered: Google is aware of the URL and will decide whether or not to crawl it
- Crawled: Googlebot has fetched the web page’s HTML source, its linked CSS styles, scripts, images and other content, has attempted to render it using a headless Chrome browser — and in the process, collected any error information like 404s or server timeouts
- Indexed: A Google algorithm has extracted the content from the rendered page and organized it for storage and ranking in its database
Official definition from Google on the exact difference between these 2 messages:
- Crawled – currently not indexed
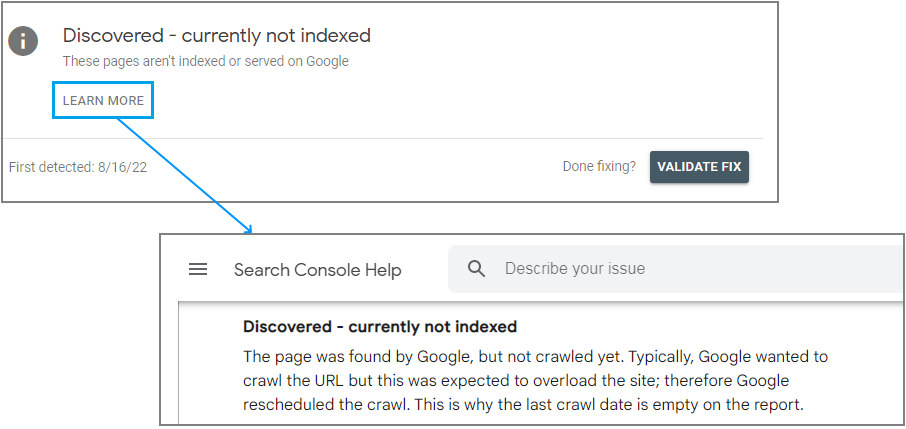
The page was crawled by Google but not indexed. It may or may not be indexed in the future; no need to resubmit this URL for crawling. - Discovered – currently not indexed
The page was found by Google, but not crawled yet. Typically, Google wanted to crawl the URL but this was expected to overload the site; therefore Google rescheduled the crawl. This is why the last crawl date is empty on the report.According to Google, the most common reason why pages end up as “discovered – not currently indexed” is server timeouts during a crawl of multiple URLs on the same site:
Despite this “overloaded” message from Google, in our experience, it’s not typical that Googlebot requests will “overload” a site. More often, it’s hard to determine exactly why a page remains discovered but not indexed. That said, if you check your logs and find that Googlebot’s crawl did in fact overload your server, you can request a slower crawl rate in Google Search Console. Note that Google does not honor the “crawl-delay” directive in robots.txt.
How Many of My Webpages Are Indexed by Google?
Putting aside the possibility that Googlebot overloaded your site, the first step in diagnosing the problem is to compare how many of your site’s pages are in Google’s index against how many are in your sitemap.
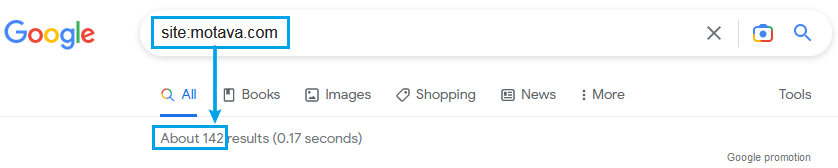
If you just need a quick estimate of the number of pages Google has indexed from your site, you can use Google’s “site:” keyword operator with a search like “site:mycompany.com“.:
To see more detail about indexed and not-indexed pages, use the Indexing » Pages report in GSC:
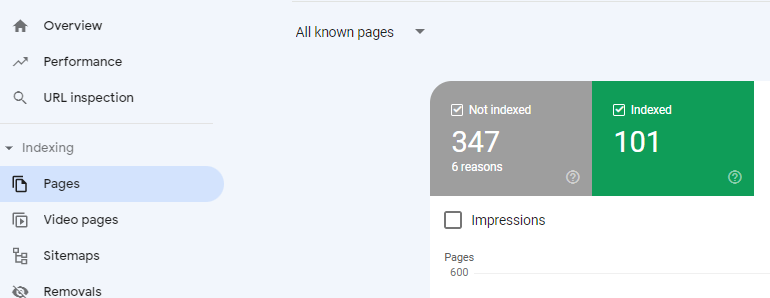
In this case, it shows 347 pages that were not indexed, for 6 different reasons. The report lists those reasons further down the page:
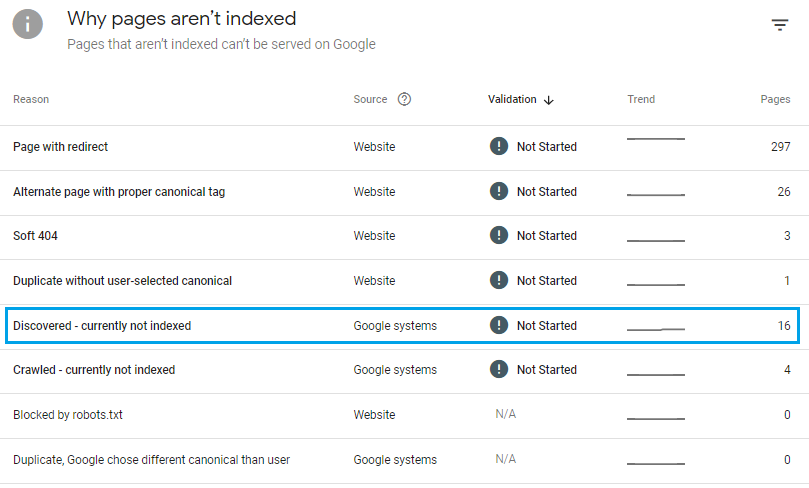
In the screenshot above, the blue highlighted row indicates 16 pages that were “Discovered – currently not indexed.” Clicking anywhere in that row will generate a report listing those pages:
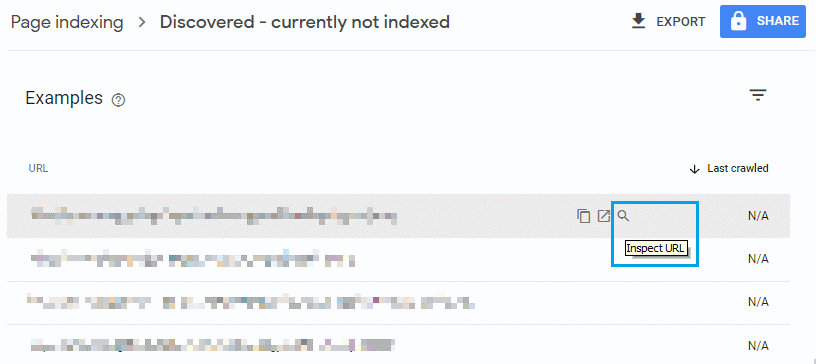
In this “Discovered – currently not indexed” list report, when you hover over a URL row, the option to “Inspect URL” will appear with a magnifying glass, highlighted in blue in the screenshot above.
How to Use the Google URL Inspection Tool
Choosing to inspect a URL will retrieve its indexation status from Google and display the URL Inspection screen:
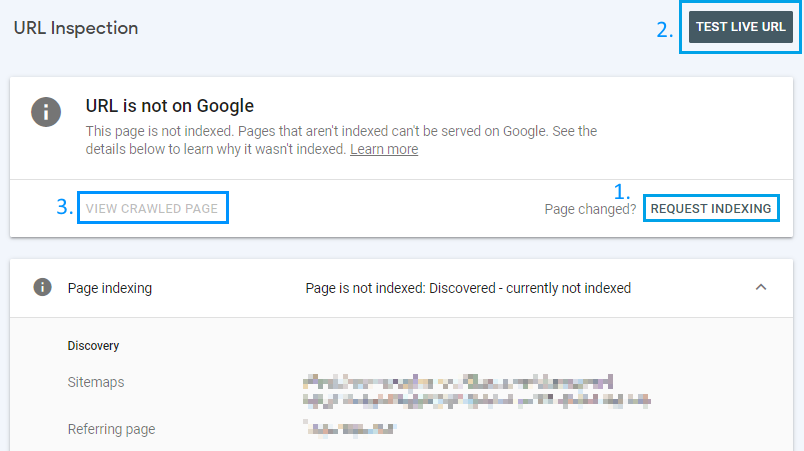
From there, you can click on any of the 3 links:
- REQUEST INDEXING. This should only be done once per page; there’s no benefit in repeatedly requesting indexing
- TEST LIVE URL. Retrieve the live URL and its components to diagnose any issues that would prevent it being indexed
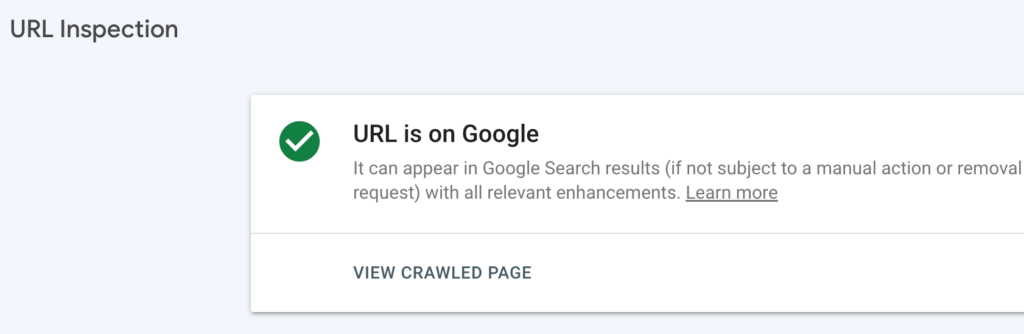
- VIEW CRAWLED PAGE. If not grayed out, this means your page has actually been crawled by Googlebot and will likely soon be added to Google’s index. Clicking on this link shows you the HTML and related components that Googlebot fetched when it crawled your page.
Google offers this helpful training video on how to use the URL Inspection tool.
How to Diagnose Problems with Google Search Console’s “Test Live URL” Button
Clicking this black button will make Google simulate crawling (fetching and rendering) the page. The resulting report may give you the reason for why the page hasn’t been indexed — but not always. The difficulty comes when everything seems okay… but your page still has not been indexed after a few days or weeks, even though it was “discovered” by Google.
Here’s an example of a report when everything looks fine, but the page still isn’t indexed:
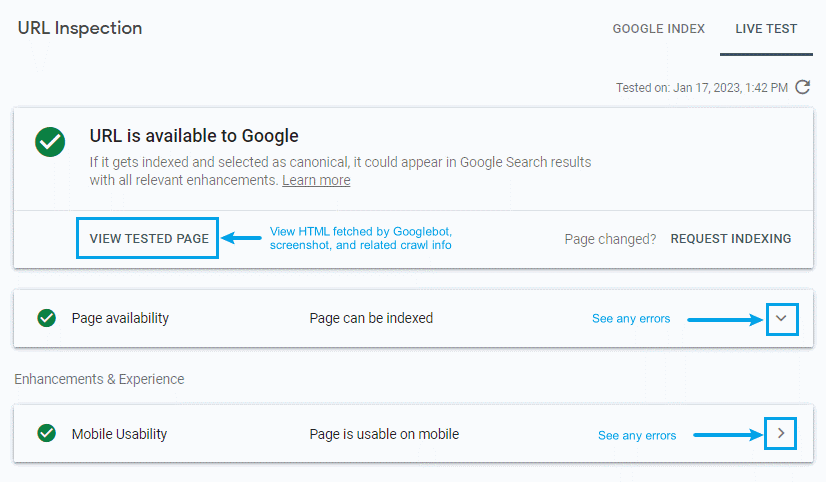
As you can see in the screenshot above, Google has no complaints about the page, despite electing not to index it yet. Note also the ominous phrasing of “If it gets indexed…” Clicking on “View Tested Page” is the next step in diagnosing potential errors.
How to Use “View Tested Page” in Google Search Console
The “View Tested Page” simulates what will happen when the Googlebot UserAgent crawls the page. It will display the HTML as fetched by Googlebot, along with a screenshot of the rendered page and extra information. The report has 3 tabs:
Tab #1: HTML. This shows you the HTML source code that Googlebot will download when it fetches the page.
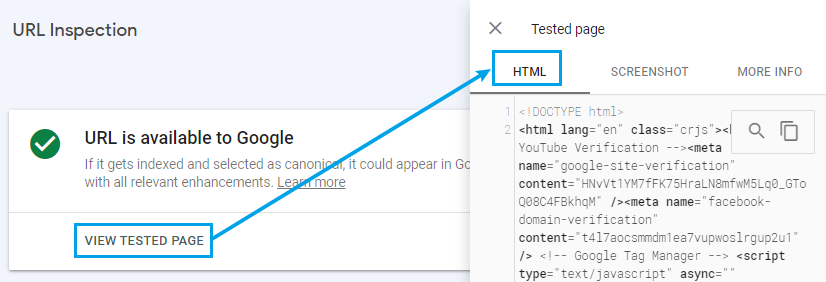
Errors in the “HTML” tab range from simple to nuanced:
- unmatched tags and comments: you can identify these by pasting source code retrieved by Googlebot into https://validator.w3.org.
- unexpected tags in the <head> of the document. Google will stop processing the <head> content — including titles and meta descriptions — if it encounters anything other than the small number of tags reserved for this area: <title>, <base>, <link>, <style>, <script>, <meta>, and <noscript>.
- confusing <iframes> and JavaScript-retrieved HTML — if the majority of the page’s content is within an <iframe>, or downloaded by an event-driven JavaScript XMLHttpRequest, that may cause problems with prioritizing your indexing job
Tab #2: Screenshot. This displays a screenshot of the rendered HTML, typically on a mobile device the test came from Googlebot’s smartphone agent:
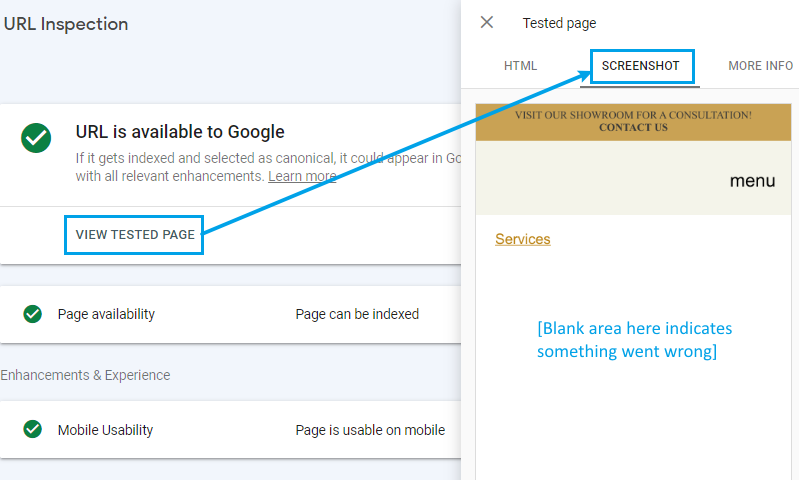
Errors in the “Screenshot” tab are easy to identify:
- blank screen — typical of an unmatched HTML tag or comment
- thin content — Google will be less likely to prioritize thin content and placeholder pages over pages with extensive, unique content
- odd rendering — for example, a pop-up that obscures the entire screen
- server error messages — if your server puts error messages in the page instead of an 510-error template
Tab #3: More Info. This report shows technical info about the response from the server:
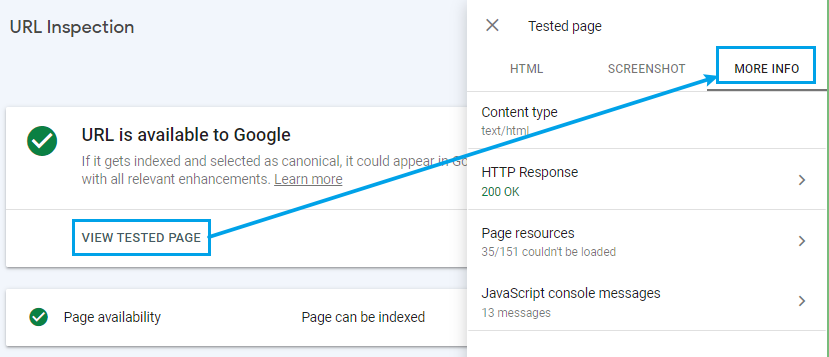
Errors in the “More Info” tab are also easy to identify:
- wrong content types (e.g., text/javascript when it should be text/html)
- unusual headers (e.g., “X-Robots-Tag: noindex” can prevent indexing)
- page resources that Googlebot was not allowed to fetch from other sites due to their robots.txt file, and which may affect the rendering of the page (e.g., third-party scripts)
- 404, 510 and similar HTTP responses indicating errors
- JavaScript console errors that might affect rendering of the page
Check Your Crawl Stats with Google Search Console
There is some delay between when GSC generates different reports, so even if the “Discovered – currently not indexed” report indicates that your page has not been crawled, you can look through the “Settings » Crawl Stats” report to see visits to your site from Googlebot:
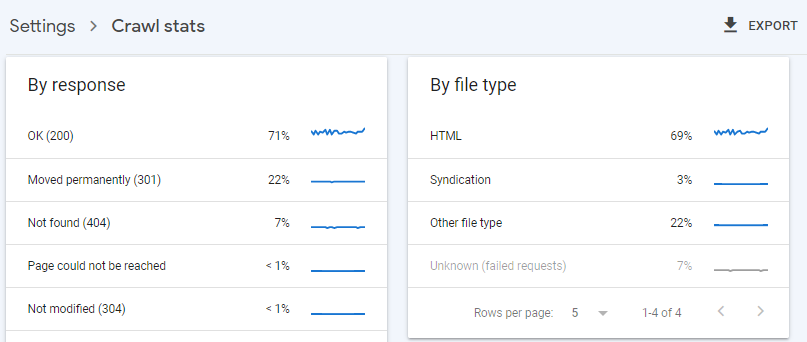
Clicking on the “OK (200)” row will show you the details of what Googlebot found when it visited your site on various dates:
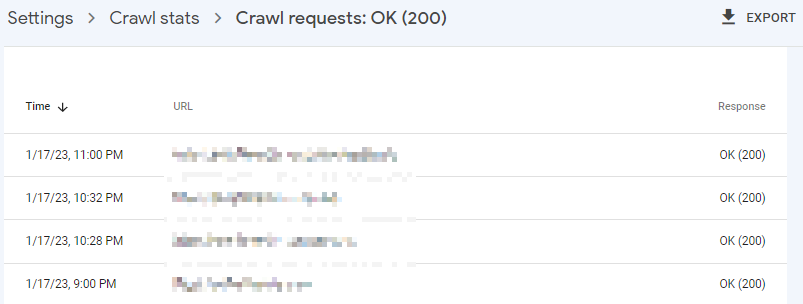
In the screenshot above, the “Response” column shows how your server responded to the Googlebot crawler: a “200 OK” response confirms that the crawler did not experience a server timeout or internal error and the page was successfully crawled.
Verify Webpage Indexing with Bing
You should test to see if Bing was able and willing to index your pages. Bing offers the same “site:” operator and its own version of GSC, “Bing Webmaster Tools.” If neither Bing nor Google has indexed your page, that is a strong indicator that something is wrong with it.
12 Obvious & Simple Reasons Why Your Page Isn’t Getting Indexed
Below is a list of some of the most common reasons why Google might not index your page or has deprioritized the page indexing/crawling. Check these off your troubleshooting list before moving on:
-
- The page is blocked by robots.txt with a line that looks something like this:
Disallow: /discounts/
Disallow: /new-redesign/ - No-index meta tag on the page that looks something like this:
<meta name=”robots” content=”noindex, nofollow” /> - It is a duplicate of an already indexed page
- Google considers it low-quality or thin content; note AI-generated content may fall into this category in the future (if it hasn’t already)
- The page returns a soft 404 error (check this using a 3rd party tool like https://httpstatus.io)
- The domain has a history of spam or penalties so new pages are deprioritized and “flagged”
- The domain is new or untrusted leading, again, to deprioritization
- The page is not properly structured with heading tags and other HTML elements or is not crawlable/indexable for some other technical reasons, like JS-generated content that doesn’t render properly or is from a site that disallows Googlebot in its robots.txt file (more on this in the next section)
- The page may not be in the correct language for the target audience / geolocation you’re using to test. There may also be an error with the href lang syntax
- The domain or page may be suffering from phishing, cloaking, malware, or other security issue
- The page is not properly submitted and indexed in Google Search Console either via sitemap (make sure the page is in your sitemap) or via manual submission
- Missing internal links – make sure the page is properly linked to from other pages on the site
- The page is blocked by robots.txt with a line that looks something like this:
9 Non-Obvious Problems & Fixes for Pages that are Discovered/Crawled but not Indexed
Here are some of the harder-to-diagnose reasons why Google might have delayed or opted against indexing your page:
1. Blacklisted.
FIX: Change the URL
Other SEO experts, like Dan Shure, have theorized that Google may have a “blacklist” of URLs that are low-priority (or worse, zero priority) for indexing. If you are confident that you’ve fixed any problems with the page, but it still isn’t getting indexed after your request, according to this theory, it means that Google has added that specific URL to the blacklist for your site. This theory hasn’t been proven, but some SEOs have reported success with copying the page content, unpublishing it, republishing the copied content with a new URL slug, and then requesting indexing.
If this route is taken, make sure to add in a 301 redirect rule from the old URL to the new one and fix any internal links to the new, final URL to avoid redirected internal links. The sitemap should also be updated with the new URL if this isn’t done automatically by your CMS.
This approach did not ultimately fix the issue we were having, but it was one of the first things we tried.
2. Unimportant Content.
FIX: Build More Links and Optimize Site Structure
Google does not guarantee to index 100% of your content — in fact, Google’s John Mueller has said that it’s normal to have about 20% of your site content not indexed. For example, it wouldn’t make sense for Google to index your privacy policy or terms of use pages. The 80% that is indexed is presumably what Google decides to be the site’s most valuable content. To that end, if you can’t easily improve your content quality, you should try to build more inbound links and organize your site to prioritize your most valuable pages:
- Make sure they are not more than 3 clicks away from the home page
- Make sure, to the extent possible, that the content is useful and unique
- Add internal links in the body of blog posts and site pages targeting the pages you want indexed
- Add external links on your social media profiles and other owned properties
- Leverage any relationships you may have with other websites to build non-owned external links to the page
- Utilize correct spelling and grammar
This fix is obviously one that would take some time to execute and is quite subjective, so you may want to save this for last and as part of a holistic approach to improving and optimizing your website.
Furthermore, optimizing and improving the content on your website should be something that is done regardless of index-status.
If getting more backlinks sounds daunting, we encourage you to review our link-building services and contact us using the chat box below.
3. Suspect Links.
FIX: Disavow Spammy Backlinks
If your backlink profile has an inordinately high percentage of spammy and/or compromised sites, Google may delay or decide against indexing your content. Using a tool like SEMRush, you can identify the overall toxicity of your backlink profile and export the most toxic links for you to submit to Google’s disavow tool.
After you’ve disavowed spammy backlinks on Google, you should synchronize them with your ranking tool, whether SEMRush or Ahrefs, so that they ignore those backlinks:
Ahrefs: Dashboard → Disavowed Links → Add Manually

SEMRush: Backlink Audit → Review Backlinks → Move to Remove List

4. You’re Not Seeing What Googlebot Sees.
FIX: Resolve Discrepancies
If your page loads external JavaScript and CSS files from third party sites, they may have a robots.txt file that disallows Googlebot from fetching those resources. If those scripts dynamically create content on your page, then Googlebot will not see it. For example, if one of your pages uses a third-party <script> that creates a nice, swipeable flipbook on your page, Googlebot will only render and crawl the contents of that flipbook if the robots.txt file on the third-party server allows robots to crawl the script. Without the rendered flipbook, your page risks looking like thin content, not worthy of indexing.
Generally speaking, you should check to see if the headers and HTML that Googlebot retrieves are mostly the same as what you get from a typical browser. To see which resources were not loaded by Googlebot, use the “URL Inspection Tool” and then click on View Crawled Page → More Info [tab] to see the resource loading results:
![View Crawled Page → More Info [tab] to see the resource loading results](https://b670873.smushcdn.com/670873/wp-content/uploads/2023/04/to-see-the-resource-loading-results-1024x272.png?lossy=0&strip=1&webp=1)
This will show you files that Googlebot did not retrieve, and thus can’t index:
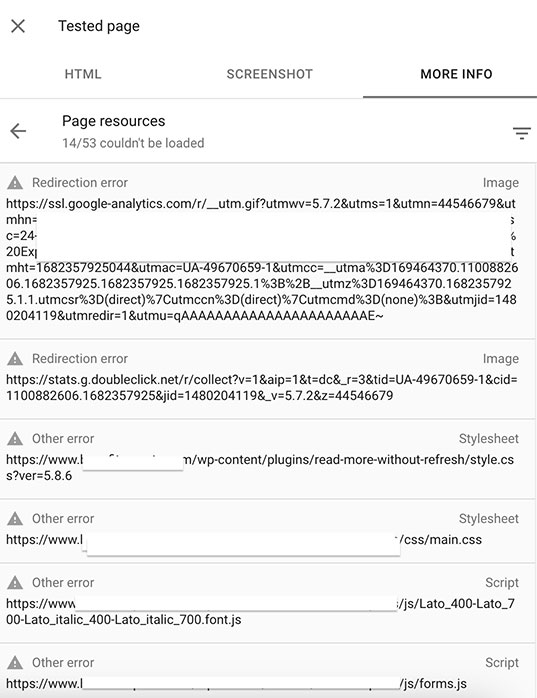
5. Client-side or Server-side Errors.
FIX: Debug and Request Re-Indexing
In the aforementioned “View Tested Page » More Info” report, Googlebot tracks any resources it could not load, the headers returned by the page, the HTTP response code (200 vs. 404 vs 510), and JavaScript console messages. You should review these console messages encountered by Googlebot to see if any relate to the way the page would be rendered. For intermittent server-side errors, match the page’s crawl dates against drops in traffic in Google Analytics during the same periods to see if your site was down when pages were crawled.
6. Wrong Canonical.
FIX: Improve Content on, and Links to, Your Chosen Canonical
Google may not have indexed your page because it found another page on your site with similar content — and decided that the other page was the canonical version of that content.
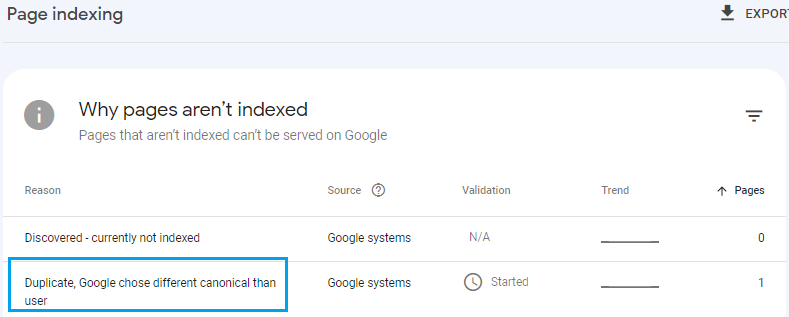
Consider a scenario where you duplicate a page listing your best-selling products, with the intention of updating it — but you didn’t remove the old page. If the content on the new page isn’t very different from the old one and and you don’t update the many internal links on your blog pointing to the old page — then Google might (and almost certainly will) choose the original, older page as the canonical page for the list of best-selling products and not index the new one you created. To find the pages where a different URL was chosen as canonical than the one explicitly provided, go to the GSC “Page Indexing” report:
To fix this, improve the content on your new page to differentiate it from the old page and update the links throughout the site to point to the newer page, adding in a 301 or 302 redirect if relevant.
7. X-Robots Tag Noindex
FIX: Remove noindex from X-Robots Tag
There is another way to noindex a page in Google. It is called the X-Robots Tag and it is delivered via your server headers typically through a CDN like Akamai. The X-Robots tag works just like the meta robots tag noindex, except it is served in the server response headers. You can find this by testing the URL with Google Search Console’s URL Inspection Tool.
You may also find this in Google Developer Tools within the headers section. To do this, right click on a page and choose Inspect in Chrome to open Dev Tools.
In the top menu that appears click Network.
Next, right click on the Refresh button in your and select Empty Cache and Hard Reload.
You will see an HTML document icon with the page’s URL in the Name.

Select it and in the pane next to it you should see a menu tab called Headers. Select this and scroll down until you start seeing headers starting with x-. If you see one that says X-Robots: noindex, this page is blocked from indexation.
To fix this you will have to request your web admins make a change to remove the rule that serves the noindex tag to Googlebot for the page(s) in question.
Note, that a CND like Akamai can deliver the x-robots tag only to search engines like Googlebot, so you might not see it in your browser. You can’t spoof Googlebot to test it because they will uses the IP address to verify the real Googlebot. So, you must use the URL Inspection Tool for a valid test in many cases.
8. Dropped HTML Tags
FIX: Verify tags via URL inspection tool & fix any inconsistencies.
Sometimes, when a page is rendered in the browser, HTML tags will be dropped. On our page in question, we noticed that the DOCTYPE tag was missing in the rendered HTML. Now, this would not be a sound reason for Google to not index the page, but if other tags are dropped as well, Google might be fooled into thinking it’s a totally different type of page, or it might not be able to fully read the content.
Check your rendered HTML in Google’s URL inspection tool against the HTML you see in your browser. Make sure the important HTML tags are all there. Again, it’s possible, that Googlebot fetches a different rendered version than the one seen as a user, so testing in Search Console is always recommended.
9. Last Resort – Use Backlink Indexing Tools
9a. 3rd Party Tools
If none of these fixes work, then you can try a backlink indexer. These are paid services to which you can submit a URL; the service will try to get Google to index it. These services don’t publish their internal workings, so there is a risk that it may be via a gray- or black-hat technique. Proceed with caution!
We did not and have not tried any of these 3rd party tools, but did try Google’s indexing API, outlined below.
Some other indexing tools that we did not test nor vouch for can be found below. Use at your own risk!
- IndexMeNow
- Omega Indexer
- SmartCrawl Pro WordPress Plugin
- OneHourIndexing
- SpeedLinks
- Indexification
- SpeedyIndexBot (Telegram)
9b. Google Indexing API
This is also a last resort, since it can be abused and go against Google’s best practices and guidelines…but, guess what, it’s what ultimately got our problematic page indexed.
So, proceed at your own risk and we recommend you do not abuse this approach.
Google provides a backlink indexing API tool, but they ask that you use it only for job and events postings only. You can find out more about it here.
With all of these warnings and guidelines disclosed, here’s how we implemented this feature to get our page indexed within just a few hours. RankMath, a popular WordPress SEO plugin, put together a guide and free integration within their WordPress plugin.
We don’t actually use RankMath for our sites, but we may have to start after this revelation. The plugin is only available for WordPress, which is the platform our problem occurred on, luckily. If you’re using a different platform, you may have to build out the API with a developer’s assistance.
RankMath put together a detailed and easy-to-follow tutorial at their website here. No coding is required and a semi-proficient, but non-technical person could complete this within 15-30 minutes.
Once installed, just hit Instant Indexing: Google Update on the desired page. Within hours, this page that was not indexed for over a month, went through practically all the troubleshooting steps prior to this, was indexed.
While this fix ultimately got our page indexed, it isn’t the long term solution we want. For long term health, many of the other points on our checklist should be addressed and corrected or optimized.
The top priority items to look into would be:
- Pruning or expanding thin content pages
- Optimizing low quality pages
- Adding internal links
- Optimizing page speed; minimize the use of sluggish plugins
- Improve external link quality
Have you run into an unruly page that won’t get indexed by Google?
Let us know what ultimately fixed it or if you need assistance getting it fixed!




{kind=link}